Automatiser un diagnostic SI pour ses prospects : de l’idée à l’architecture (partie 1/3)
Chez Oguhnas, une question revient régulièrement lors des premiers contacts avec des dirigeants de PME : “Comment savoir si mon infrastructure est à risque ?” Souvent la fragilité est là, perceptible, mais personne n’a pris le temps de la cartographier. Ce projet est né de ce constat : concevoir un outil qui génère un rapport d’audit SI personnalisé, automatiquement, en moins de 10 minutes et sans rendez-vous préalable.
Cet article est le premier d’une série de trois. Il couvre la phase de conception : pourquoi cet outil, comment le questionnaire a été structuré, comment fonctionne le scoring contextuel, et quels choix techniques ont été faits avant de commencer à coder. Les parties 2 et 3 couvriront ce qui a changé pendant l’implémentation, puis ce que le produit final est devenu par rapport à l’objectif initial.
Sommaire :
Le point de départ : qualifier sans imposer
Un consultant indépendant sur des sujets IT passe beaucoup de temps à expliquer ce qu’il fait, pourquoi c’est utile et à quel point la situation du prospect mérite qu’on s’y attarde. Une bonne partie de ce temps se passe avant même qu’un mandat soit signé, parfois avant même qu’un premier échange ait eu lieu.
Le problème n’est pas le contact en lui-même. C’est le déséquilibre : le prospect ne sait pas encore si son sujet est vraiment urgent et le consultant ne peut pas le lui démontrer sans un audit, ce qui prend du temps et ne se fait pas pour rien. On tourne en rond.
L’idée d’un outil d’acquisition automatisé vient de là. Donner la valeur en premier, sous forme d’un rapport concret et personnalisé, sans exiger de rendez-vous à froid. Si le rapport est honnête (c’est-à-dire s’il identifie réellement les fragilités et non pas juste ce qu’on veut vendre) il est un premier diagnostic. Le prospect repart avec quelque chose d’utile. Oguhnas repart avec un lead qualifié, des données structurées sur le contexte de l’entreprise, et un prétexte naturel pour la suite.
Ce n’est pas du marketing déguisé en outil technique. C’est un outil technique qui, par construction, génère aussi un contact qualifié. La différence est dans la qualité du contenu produit.
Concevoir le questionnaire : deux phases distinctes
Le parti pris dès le départ est de séparer deux types d’information : ce qui ne va pas (les fragilités techniques) et à quel point c’est grave pour cette entreprise en particulier (le contexte).
Phase 1 — les 20 questions d’évaluation
La première phase couvre 20 questions Oui/Non réparties sur quatre axes :
- Sécurité et accès (5 questions) : double authentification, gestionnaire de mots de passe, sensibilisation phishing, localisation des données sensibles, procédure d’incident.
- Sauvegardes et continuité (5 questions) : automatisation quotidienne, test de restauration, isolation physique, procédure de reprise, connaissance du délai de remise en service.
- Infrastructure et supervision (5 questions) : systèmes à jour et supportés, mises à jour de sécurité régulières, documentation de configuration, alertes sur les services critiques, autonomie de diagnostic en cas de panne.
- Pilotage et maîtrise (5 questions) : inventaire des outils et services, réversibilité vis-à-vis du prestataire, gouvernance des nouveaux outils, processus métier documentés, identification du principal goulot d’étranglement.
Le format Oui/Non est volontaire. Il force une réponse tranchée et évite les zones grises qui diluent le diagnostic. Une réponse “Non” sur “avez-vous testé une restauration complète dans les 6 derniers mois ?” dit quelque chose de précis. Un “partiellement” ne dirait rien.
Phase 2 — les 9 questions de contexte
La deuxième phase ne mesure pas les fragilités : elle mesure l’exposition. Neuf questions couvrent le profil de l’entreprise :
- Taille (1-10 / 11-50 / 51-250 salariés)
- Secteur d’activité
- Ressource IT disponible (équipe interne, prestataire, aucune)
- Clients dans un secteur régulé
- Services numériques exposés aux clients
- Hébergement de données sensibles
- Connaissance des obligations réglementaires
- Usage de l’IA par les équipes
- Existence de règles d’usage de l’IA
Ces réponses ne donnent pas de score. Elles servent à calculer des modificateurs qui amplifient ou maintiennent les scores de la Phase 1. Une PME de 200 personnes sans ressource IT dédiée, qui héberge des données médicales et dont les équipes utilisent des outils d’IA sans cadre défini, ne présente pas le même niveau de risque qu’une structure de 10 personnes avec un prestataire en place.
Un dernier détail de conception : l’email est collecté en dernier. Le prospect a répondu à 29 questions et sait que quelque chose de concret va arriver. À ce stade, fournir son adresse est une suite logique, pas une barrière.
La formule de scoring
Pour chaque question de Phase 1 dont la réponse est “Non”, le score est :
score = poids de base + somme des modificateurs actifs
Le poids de base va de 1 (impact modéré) à 3 (risque critique de base). Les modificateurs viennent des flags dérivés de la Phase 2. Un flag est une variable vrai/faux calculée depuis les réponses contextuelles. Par exemple :
ctx_sensitive_dataest vrai si l’entreprise héberge des données sensiblesctx_no_it_resourceest vrai si aucune ressource IT n’est disponible, et ainsi de suite.
Les seuils de priorité
| Score final | Priorité | Délai d’action |
|---|---|---|
| ≥ 4 | 🔴 Critique | Dans les 30 jours |
| 3 | 🟠 Important | Dans les 3 mois |
| 1-2 | 🟡 À planifier | Dans la feuille de route |
| 0 (réponse Oui) | 🟢 Maîtrisé | Aucune action requise |
Un exemple concret : la question sur la double authentification a un poids de base de 3. Si l’entreprise héberge des données sensibles (flag ctx_sensitive_data actif, +1) et propose des services numériques à ses clients (flag ctx_client_facing_service actif, +1), le score final est 5 : critique avec un délai d’action recommandé de 30 jours. Si aucun de ces deux flags n’est actif, le même “Non” donne un score de 3 : important, mais pas dans les 30 jours.
Le mécanisme transversal IA
Un mécanisme transversal s’applique sur trois questions spécifiques si le flag ctx_ai_unmanaged est actif : usage IA “chacun se débrouille” sans règles définies. Ces trois questions portent sur la localisation des données sensibles, l’inventaire des outils et la gouvernance des nouveaux services. Chacune reçoit +1 supplémentaire.
La logique est directe : un usage non encadré de l’IA est une porte d’entrée pour l’exfiltration de données, la prolifération d’outils non validés, et la perte de traçabilité sur ce qui circule à l’extérieur de l’entreprise. Ignorer ce risque sur ces trois points spécifiques serait un angle mort.
Sept flags contextuels
Les flags calculés depuis la Phase 2 sont au nombre de sept :
ctx_size_51_250: entreprise de 51 à 250 salariésctx_regulated_client: clients dans un secteur régulé (y compris “je ne sais pas”)ctx_client_facing_service: services numériques exposés aux clientsctx_sensitive_data: données sensibles hébergéesctx_no_it_resource: aucune ressource IT dédiéectx_unknown_regulations: obligations réglementaires partiellement ou non identifiéesctx_ai_unmanaged: usage IA sans gouvernance
L’intérêt de cette structure : deux entreprises qui répondent “Non” aux mêmes 20 questions n’ont pas le même rapport en sortie. Le scoring est personnalisé sans que le prospect ait besoin de le savoir.
La structure du rapport PDF
Le rapport suit cinq sections dans l’ordre :
- Page de couverture : titre, prénom, nom, entreprise, date.
- Synthèse : radar chart sur 4 axes (un axe par catégorie de Phase 1) plus les compteurs par niveau de priorité.
- Plan d’action priorisé : les points non maîtrisés classés par niveau avec pour chacun : l’action recommandée, une piste de réflexion concrète et un lien vers l’article de blog associé sur oguhnas.fr.
- Annexe A : tableau des réponses Phase 1 par catégorie.
- Annexe B : tableau des réponses Phase 2 (contexte).
L’appel à l’action dans le rapport varie selon le nombre de points critiques. En dessous de 1 critique, il n’y a pas d’appel urgent. Entre 1 et 2 critiques, le texte est “des points d’attention importants ont été identifiés”. Entre 3 et 4 : “plusieurs points critiques nécessitent une attention rapide”. À 5 et au-delà : “votre infrastructure présente des vulnérabilités majeures”. Ces seuils sont configurables dans la base de données, rien n’est codé en dur.
Le rapport n’est pas un verdict. C’est un point de départ structuré pour une conversation.
L'outil décrit dans cet article est disponible
29 questions, rapport personnalisé en moins de 10 minutes. Aucun rendez-vous requis.
L’architecture technique retenue
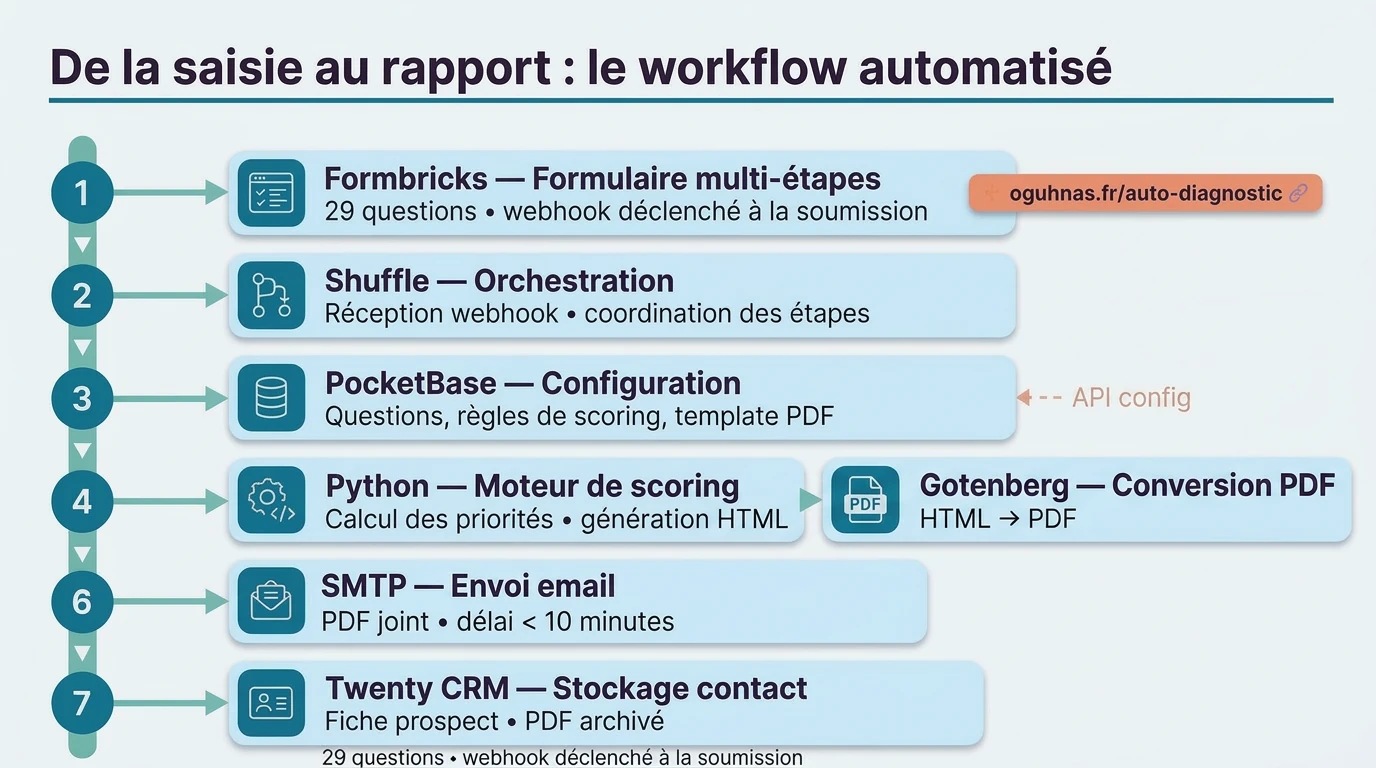
Sept composants, tous open-source et hébergés sur les serveurs Oguhnas :
| Composant | Rôle |
|---|---|
| Formbricks | Formulaire multi-étapes, déclenchement automatisation, purge des réponses |
| Shuffle | Orchestration de l’automate |
| Python | Analyse des réponses et génération du rapport HTML |
| Gotenberg | Conversion HTML (format web) vers PDF |
| SMTP | Envoi du PDF par email au prospect |
| PocketBase | Base de données des audits, questions, modificateurs, template |
| Twenty CRM | Stockage du contact prospect et du PDF |
Le choix de tout héberger en propre n’est pas un dogme. C’est une contrainte de cohérence avec le positionnement d’Oguhnas : ne pas dépendre d’un éditeur externe pour des données sensibles et garder la main sur la configuration complète du système. C’est d’ailleurs ce que nous recommandons à nos clients.
Pourquoi Shuffle
Shuffle est un outil d’orchestration de workflows qui a des limites documentées (on y revient en partie 2). Le choix de le conserver malgré ces limites repose sur un argument simple : Shuffle est déjà utilisé sur d’autres projets Oguhnas. Introduire un nouvel outil d’orchestration pour ce seul projet aurait signifié une deuxième courbe d’apprentissage, un deuxième périmètre de maintenance et une deuxième surface d’exposition en cas de problème. Ce n’était pas justifié.
La règle générale sur l’outillage interne est la même que pour les clients : on n’ajoute un composant que si aucun composant existant ne couvre le besoin. On ne change pas d’outil parce qu’un autre semble mieux sur le papier.
Vous avez un projet d'automatisation sur la table ?
Même logique : on part de ce que vous avez, on n'ajoute que ce qui manque vraiment.
Données personnelles et architecture
Aucune donnée personnelle n’entre dans PocketBase. Les coordonnées du prospect (prénom, nom, email, entreprise) vont directement dans Twenty CRM. Les réponses brutes sont purgées de Formbricks dès que le workflow est terminé. Ce qui reste dans PocketBase : les scores, les flags contextuels et les compteurs (des données agrégées sans identification possible).
Ce n’était pas une contrainte ajoutée après coup. C’est une décision d’architecture prise dès la conception, parce que c’est la façon la plus propre de traiter des données de prospects.
Estimation initiale
Le calendrier estimait au démarrage 10 à 15 heures de développement réparties sur sept étapes (PocketBase, Gotenberg, moteur Python, Formbricks, Shuffle, tests, mise en production), avec un délai de traitement de moins de 10 minutes entre la soumission du formulaire et la réception du PDF.
Ces estimations étaient raisonnables sur le papier. En pratique, plusieurs points ont évolué pendant l’implémentation, c’est le sujet de la partie 2.
Ce que cette architecture permet déjà
Avant même de commencer à coder, la conception du modèle de données a été guidée par une contrainte : le moteur doit pouvoir traiter n’importe quel type d’audit, pas seulement le diagnostic initial. Si la structure fonctionne pour 20 questions sur 4 axes avec 7 flags contextuels, elle doit fonctionner de la même façon pour un diagnostic sur la maîtrise des risques IA, ou pour un audit de cybersécurité de base destiné à une PME industrielle.
Ça change profondément la façon dont on modélise les données. On ne code pas “les questions du diagnostic SI”, on code “un moteur qui évalue des questions selon une configuration stockée en base”. La différence n’est pas visible pour le prospect. Elle est considérable pour la maintenance.
La partie 2 détaille les six pivots de conception qui ont modifié l’architecture pendant le développement, et pourquoi chaque modification était la bonne décision.
Votre SI mérite un regard extérieur
30 minutes pour identifier les deux ou trois points qui freinent vraiment vos opérations, sans audit complet ni engagement.
Planifier un échange